

前言
2026年4月30日,流星夜。确认伪人:一名。
早上七点已至,欢迎来到心猿社丨AI省流日报,请工酱开始发言。
优质活动与开源产品
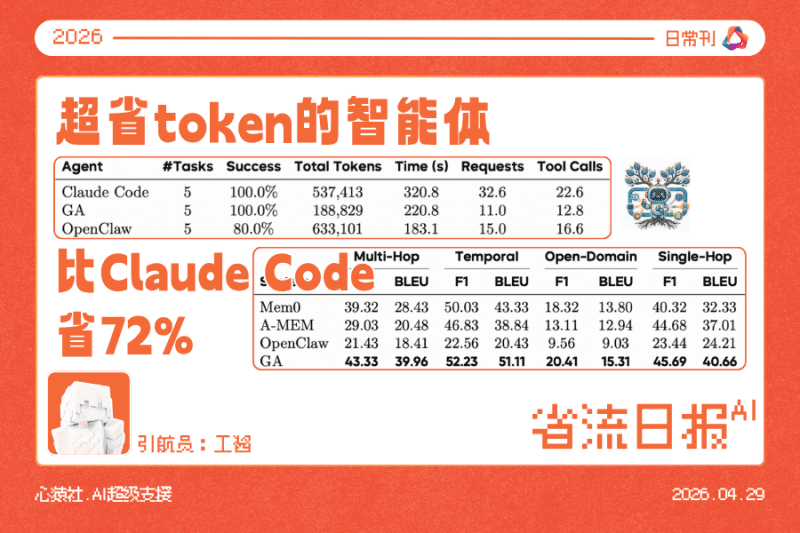
腾讯ima上线copilot模式,用户可领养个性化东北味熊猫AI合伙人【深度查验】
该模式整合知识库、长期记忆系统和全场景感知能力,无需上传文件即可自动识别浏览内容并辅助分析。
但不建议接个API当主力,长期使用。它是网络端服务,数据隐私是问题。它的框架不开源,也不知道省不省钱(tokens),会不会有坑。所谓的个性化,其实自己接个Skill就能行。数据库功能…看着送30GB空间挺好,但你上传的资料是无法下载回本地的,我已经能想象到以后迁移资料的痛苦。
所以真想用AI代理(OpenClaw),还是老老实实弄个本地版本。
思维必看
物理启发深度学习EMNN实现光子逆向设计17000倍加速【深度查验】【确认伪人】
该网络由局部电磁场求解器与Huygens-Fresnel Stitch连接器组成,建模误差较数值模型降低两个数量级,成功设计计算元系统。
在芯片设计领域,已知“芯片结构”,可以用物理公式正向算出“光的效果”;但反过来,知道“光的效果”,物理公式却无法直接推导出该用什么样的“芯片结构”。
如果只是做成插件,公式依旧只能做正向计算,解决不了从效果反推结构的逆向难题。
但嵌入神经网络层后,训练时,模型每猜出一个结构,内置的公式层就立刻按物理定律算出这个结构所产生的光效(因为是直接从公式推导,所以答案不会错),并给出精确的误差评分。
大模型再根据误差评分,进行自监督学习。这样,大模型就学会了“根据光效反向猜测结构”。
谷歌科学家利用AI实证研究助手ERA加速真实科学研究【深度查验】
该工具已被应用于流行病学、宇宙学、大气监测等场景,此前已在细胞生物学等六大跨学科难题上提出创新解决方案。
智源2050论坛探讨数字生命上传:分步逼近路径已清晰【深度查验】
研究员雷博提出Brainu融合方案,可将fMRI、脑电等脑信号统一Token化编码,与会科学家共识是数字生命无法一步实现。
比如,大脑结构复刻路线,最有力的实验案例就是那只“赛博果蝇”,它有力地证明了“大脑神经网络”和“智慧”存在高度联系,但这个案例实际上还有力地支持了拟合路线。
你要找到二者之间的联系性:所谓复刻大脑结构,不就是在复刻一个已经训练好的神经网络吗?所谓拟合路线,不就是让人工神经网络接近生物神经网络吗?
你是否想过:身边的人,真的都有主观感受吗?你会说:“瞎扯!”但仔细一想,人真的证明过吗?有没有一种可能性,你只是被洗脑了。教科书告诉你“生命有主观感受”,周围人也这样说,于是你便过度假设:生命一定有主观感受。这就像误采毒蘑菇,因为你认识香菇、草菇能吃,所以过度假设眼前不认识的毒蘑菇也能吃。
你要骂我了:这不就是怀疑论吗?其实我最担心的,就是你将推演论过度假设为怀疑论。推演论真正想揭示的,不是“什么也证明不了”的虚无,而是一种认知范式。换句话说,推演论描述的是人类最根本的认识状态和认识变迁。
类似未被证明的东西还有很多。时间真的存在吗?真理真的存在吗?是“意识→物质”还是“物质→意识”?这些问题看似高深,实则可能只是我们过度假设的产物。
所以推演论不讨论“意识→物质”还是“物质→意识”,而是后退一步,阐述两者兼有的“→”。同样,在推演论的框架下,时间、真理,乃至“生命有主观感受”这些命题,我们都可以先假定它们成立,然后再通过分析它们所处的表达位置,来理解应该如何合理地对待它们。
你可能会担心:万一这些假定是错的呢?推演论中阐述:人的一切认识均是假设,即使假设被验证了也依然是假设,因为人几乎不可能测量准确。但请放松一些,把人类社会放在更长的时间尺度上看,我们不正是一次次推翻过去的假设,才抵达今天的认识吗?
所以,推演论从不害怕错误。因为它描述的就是人类最根本的认识状态与认知变迁,而人类,本来就很容易犯错。
真正关键的是:我们如何对待现有的认识,如何在犯错之后有效地自我纠正。这才是推演论真正的革命之处。
清华何秉翔分享可扩展强化学习三条边界:JustRL、无监督RLVR和On-Policy Distillation【深度查验】
该团队三项工作系统回答了RL recipe是否必须越来越复杂、人工标注成本爆炸时能走多远、密集token级监督是否“免费午餐”三个根本难题。
OpenAI硬件负责人Stanford闭门分享:自研系统已从零走到流片【深度查验】
该团队两年内完成芯片设计并实现流片,目标构建涵盖芯片、机架、网络、散热的完整系统,以重获AI运行底层控制权。
前沿模型突破
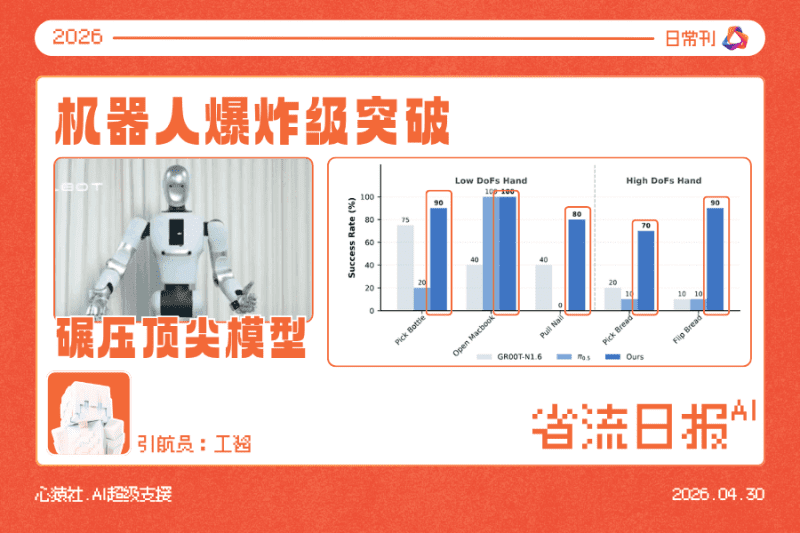
1.6B参数跨本体世界动作大模型解锁具身GPT-2时刻【深度查验】
该模型首次在数据层面实现虚实共融、人机混合数据统一利用,仅需1小时后训练即可跨具身本体自适应操控。
三维多模态基础模型OCTCube-M提升OCT分析诊断精度【深度查验】
该框架通过多模态对比学习联合分析3D OCT与二维眼底影像,在八种视网膜疾病预测等任务中显著优于传统监督模型。
学术突破
David Baker团队Nature综述:AI蛋白质设计正从造分子迈向造机器【深度查验】
该综述指出RFdiffusion等生成式AI已建立“骨架生成+序列设计+结构验证”完整流程,判断未来5-10年有望超越天然蛋白潜力。
多路超图神经网络MHGNN破解中药预测,准确率超92%【深度查验】
该框架将草药-症状相互作用建模为多重超图,采用分层消息传递与基于网络邻近度的负采样策略,在两个公开数据集上始终优于13个SOTA基线。
AutoGaze自回归眼动模块实现19倍推理加速,支持千帧4K视频【深度查验】
该轻量级模块主动移除冗余视觉patch,将token数减少4至100倍,使多模态大语言模型首次支持1000帧4K视频理解。
国内动向
寻明生科完成3500万美元A+轮融资,加速AI驱动抗体药物从头设计【深度查验】
该企业资金将用于推进创新功能抗体设计平台AuraIDE™建设,已有一款药物即将进入临床,两款进入IND开发阶段。
北大研究员王鹤获北京青年五四奖章,系本年度唯一具身智能领域获奖者
其团队在泛化抓取、物体操作、3D寻物导航等方向实现原创突破,构建以“银河星脑”为核心的端到端闭环控制体系。
国务院参事薛澜出席中瑞创新政策研讨会,谈AI创新与能源转型
该学者为清华大学苏世民书院院长,就AI技术创新与能源转型议题进行了交流。
国外动向
英伟达入股CoreWeave并推出Vera CPU,DeepSeek V4证实其GPU生产可用
该企业以20亿美元购入CoreWeave股权,后者成为首家部署Vera CPU的客户;新CPU基于定制Arm架构,拥有2270亿晶体管、88核176线程。
Anthropic年化营收突破300亿美元,正式超越OpenAI成为美国AI营收榜首
该企业80%收入来自企业端,拥有超30万家企业客户,年付费超100万美元的大客户超1000家,模型训练投入仅为OpenAI的四分之一。
AWS发布桌面AI助手Amazon Quick,打通本地应用生态并接入OpenAI最新模型
该助手基于知识图谱打通邮件、日历、Slack等应用,可主动安排会议并生成PPT;同时首次将OpenAI前沿模型接入Amazon Bedrock(托管平台)。
有点意思
18年开源老兵含泪告别:AI负荷致GitHub天天宕机,带5万星项目Ghostty迁离
Vagrant及Terraform缔造者Mitchell Hashimoto指出,AI浪潮将GitHub同时变成代码仓库、LLM训练数据池和AI Agent操作台,基础设施不堪重负。
GPT之父Alec Radford把AI扔回1930年:从未见过代码,竟写出了Python
该团队发布130亿参数talkie模型,全部训练数据来自1931年前的英语文本,验证LLM能力核心是推理而非检索,但传统OCR文本训练效率仅达人工转录的30%。
尾语
本篇日报我们和笔记端一起进行了系统性优化,页面更清爽的同时,信息的质量也提升了一个台阶。
若有意见,欢迎提案~